Notes: Production Model Deployment
Agenda:
- Model Lifecycle
- Deployment challenges
- Solutions to the challenges
- That are themselves very challenging
- There are solutions to those too
- That are also very challenging :)
Black Box Data Scientists: You put data into a Data Scientist and models and dashboards come out. We focus on models for this talk.
Process/Lifecycle: Data Warehouse -> Featurization/Transformation -> Training (Produce a model) -> Application (take weights and probabilities and generating an output) -> Validation.
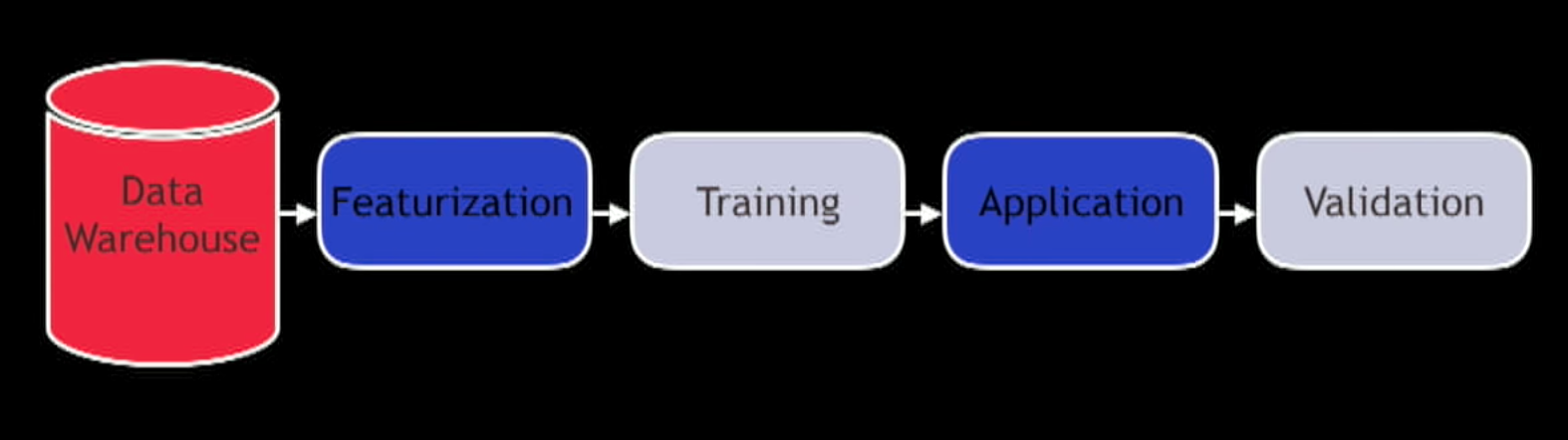
What is deploying model? What does that mean?. Deployment is sharing with other people, services and applications.
3 types of deployment mechanisms
- Building a service: Putting a model inside of an API, you give it data and it gives you a response. Example: StitchFix API gets information of a customer and tell you what items he/she might like.
- Sharing the output that is written to a file (or somewhere). Its not that important that the model is super reactive, for example: Telco companies predict churn of a customers and you build a reliable pipeline that at the end sends a bunch of emails.
- (not that common but possible): Build a model and package it as a software package (pypi) and some people can download it and use it.
What is a model?
This concept is very loosely defined in the industry.
A model is a thing that knows enough about itself to know how to apply itself. For example, trained a linear regression and there needs to be some transformations (encoding of variables or something like that)
A model consists of:
- Transformation/Featurization
- Type of model
- Weights
- And all the logic you need to apply that
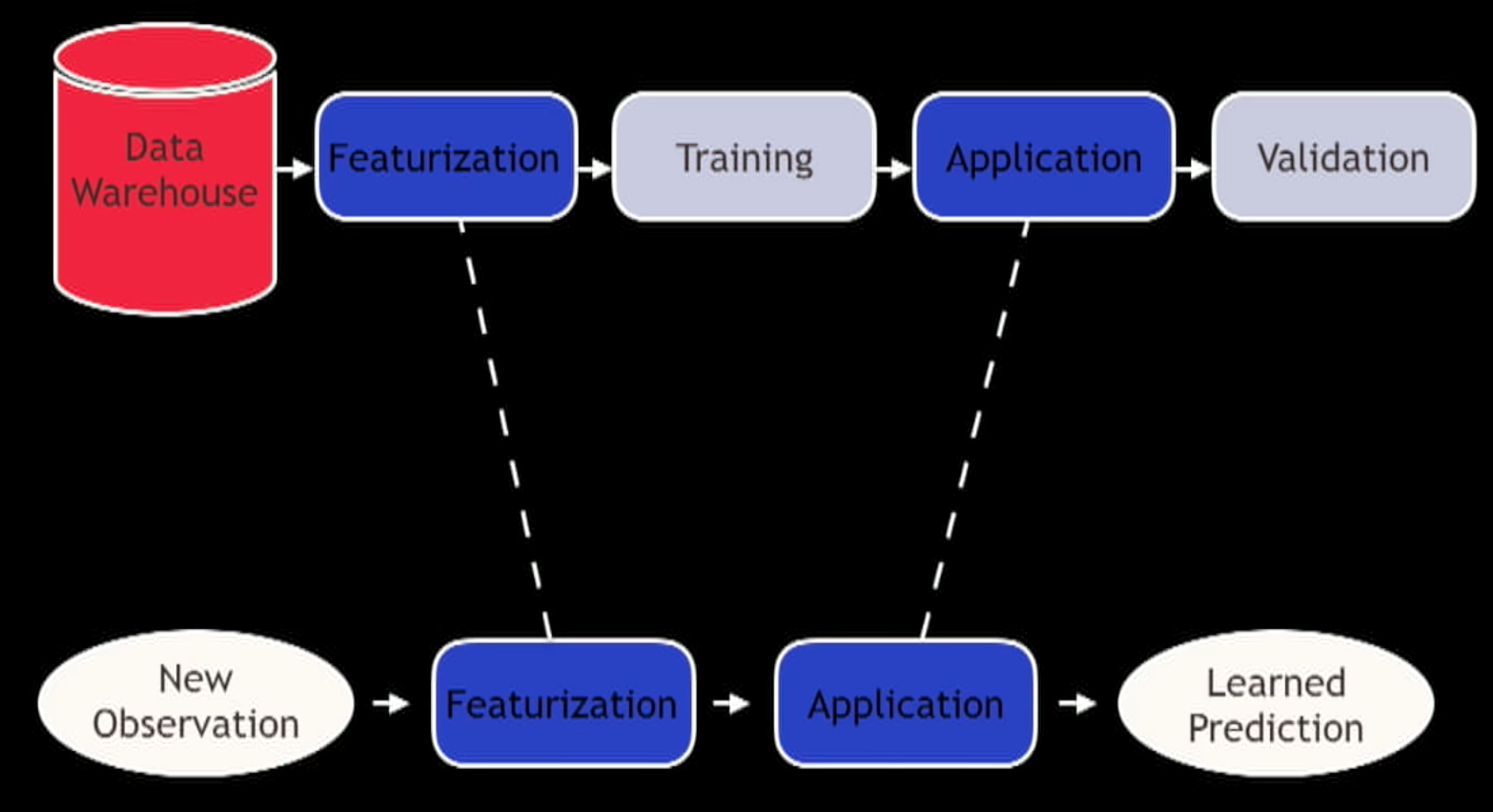
You move model thought serialization. How do you do this?
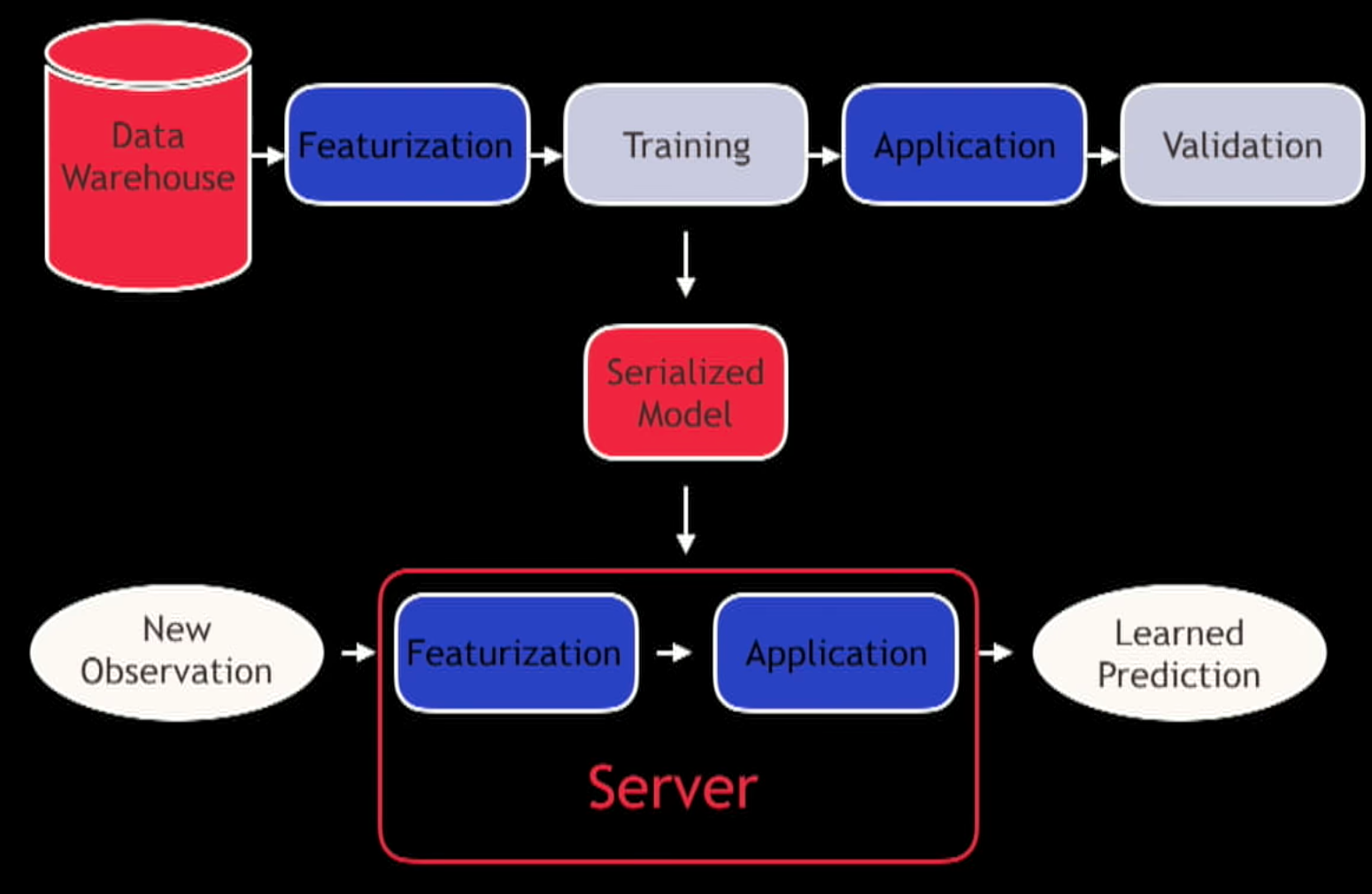
Once you get into the point where you made a model and you know you have to write it out and read it in again you need to think more than that simple interface. There you should be 3 questions:
- Does the model do what you need? - The validation offline seamed effective but is it actually making you more money/click?
- Does it meet your engineering requirements? - Throughput, latency and those things
- Is your team organized to build and support that type of model? - This type of building and deployment is very need and we are still trying to figure out how to do this effectively.
Does it function?
This is another service, you need to do logging, monitoring, do you have spike memory usage? Set up alerts.
Is it useful?. “Al models are wrong, some are useful” :)
There is only one way to find out. You need to do an experiment (A/B testing). Split between 2 or more groups and show them different models and compare the results to see if there is an statistical difference.
Is it contiues to be useful? Long term view of model quality.
If we want to be sure that the model is as good as it did in the A/B test then you should do the A/B test forever, have a population that is always in a control group (those people never get an update). This happens but might not be the best for a group of users.
You can take a look at the distribution of features, distribution of features. These might change depending on the population but it gives you and idea of what is happening in the model to catch and debug things in production.
Measure things that tell you how often you need to retrain your model. How do this features and predictions shift during time?
We don’t deploy one model, we deploy the process for repeatedly making more. When you deploy a ML model into production you are not saying “this is the best model and we should use it forever”. What it actually means is deploying the pipeline for model building and making it more repeatable.
For StichFix, there is new clients and new items coming everyday so they need to create models everyday. You can also be getting new information that make the model better.
This pipelines you need to set them up in a schedule and you need to figure out what the schedule is.
You can rebuild models in a schedule (most often nightly) or continuously.
On a schedule there is some tools like ozzie, airflow or luigi, since this pipelines tend to be very complicated.
To do it continuously the lambda architecture provides a framework for thinking about how to take in data and update model parameters and use that continuously updated model to make new predictions. This is like keeping partial estimates of the model and update those continuously.
It is possible to do this but its more complicated than an ETL pipeline.
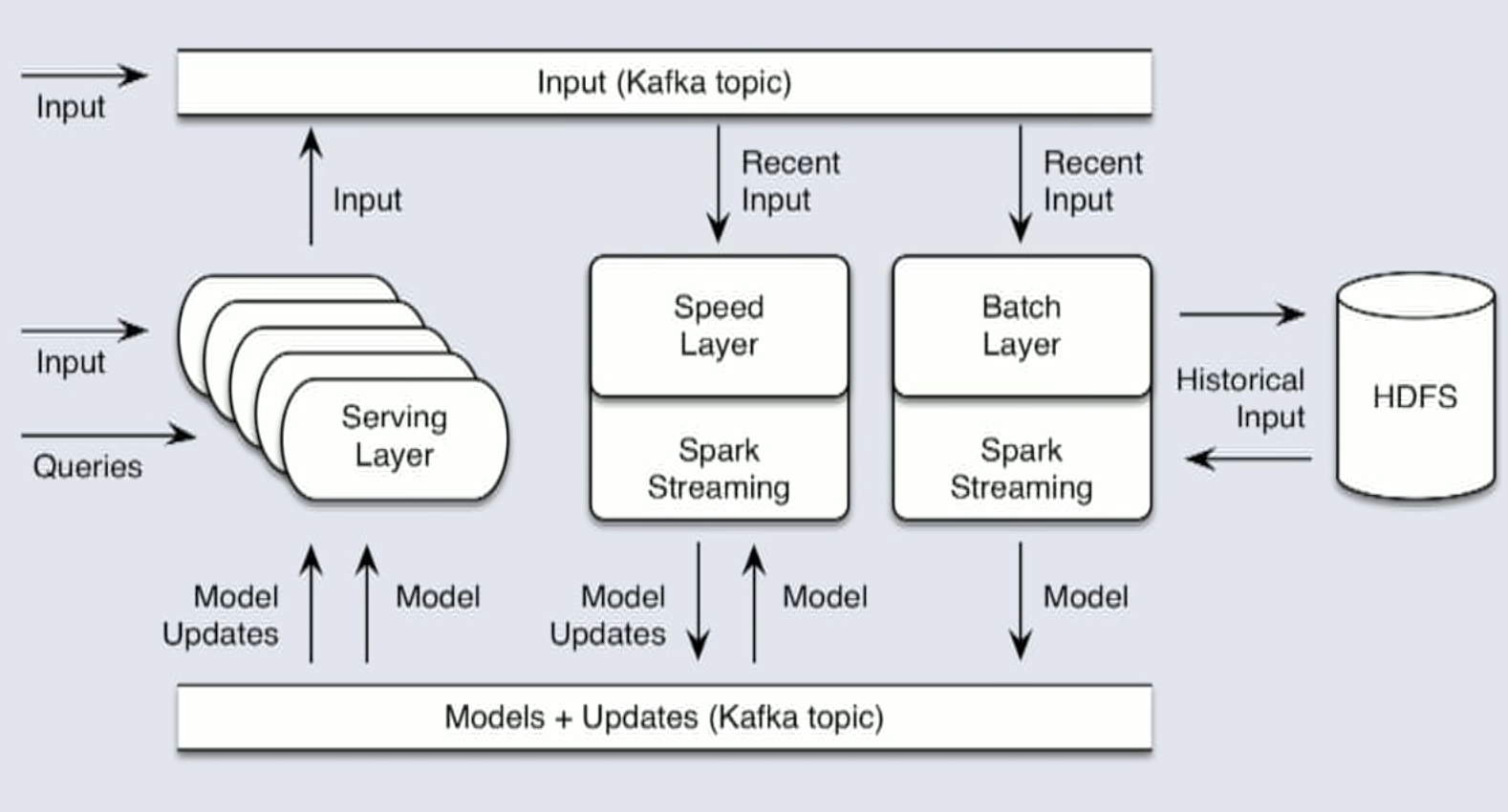
An example that needs this is Google News.
Meets requirements?
We build a model and we know its useful, ok great, do we know that it meets the engineering requirements?
This should be asked before building a model so we know what to optimize for. It’s usually done after but its recommended to take a step back and think about this before.
Do you need a system that is created nightly? Or does it need to be refreshed continuously?
Throughput
Once you have a serialized model you that is stateless you can scale the deployment by having a load balancer and more instances of the model.
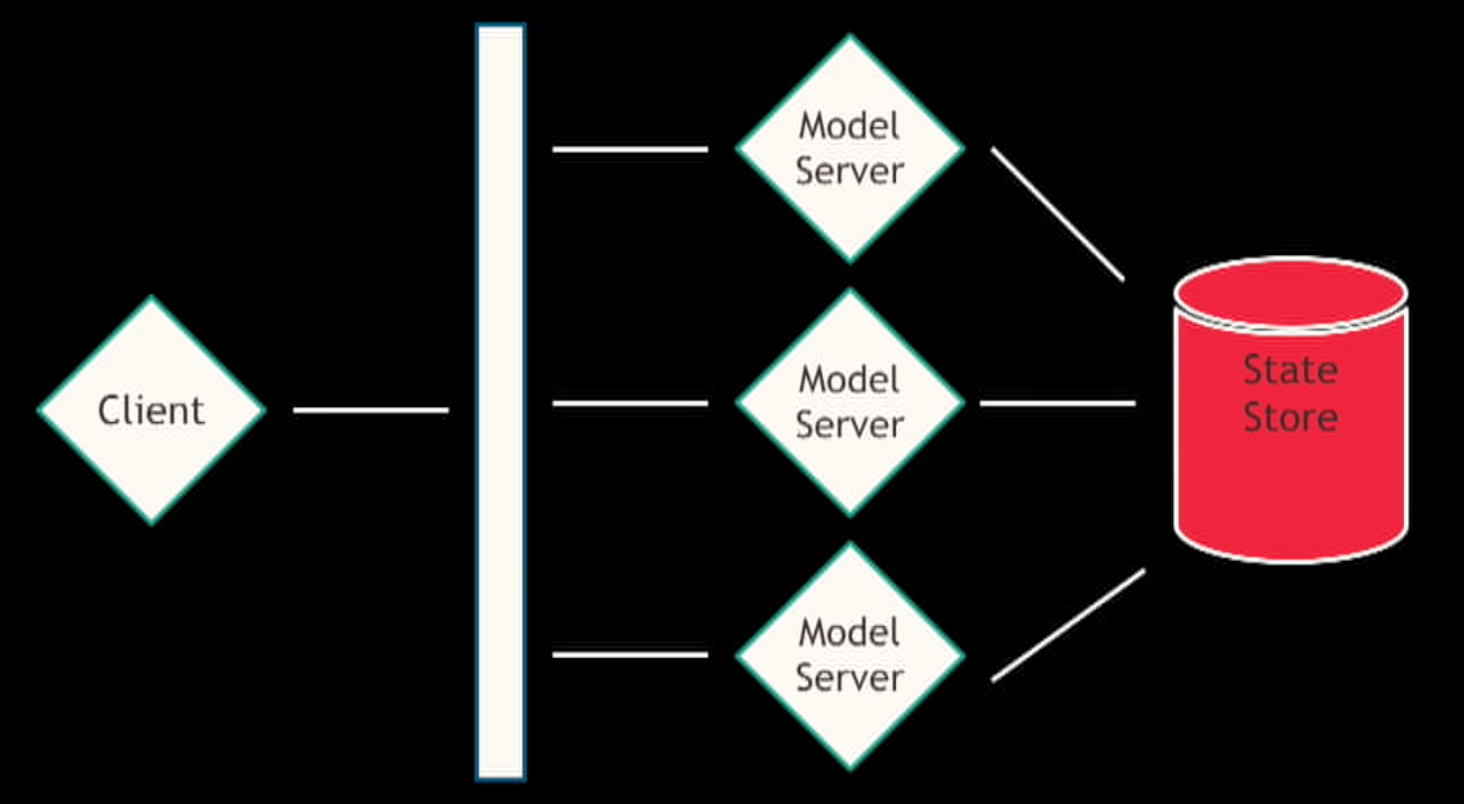
At StichFix the State Store is like a database for model parameters. So when a model is updated features and weights get pushed to the State Store and the Models Servers know how to read the data and update the parameters that are being used for applying data.
Fast enough
Having a goal ahead of time is a great idea or you get into optimizations that get your very little.
Use approximation methods, dimensionality reduction, caching, projections tricks. Basically viewing a shadow of the dataset and building a model of that instead and working with smaller data at application time.
Another common trick is to have a Feature Store.
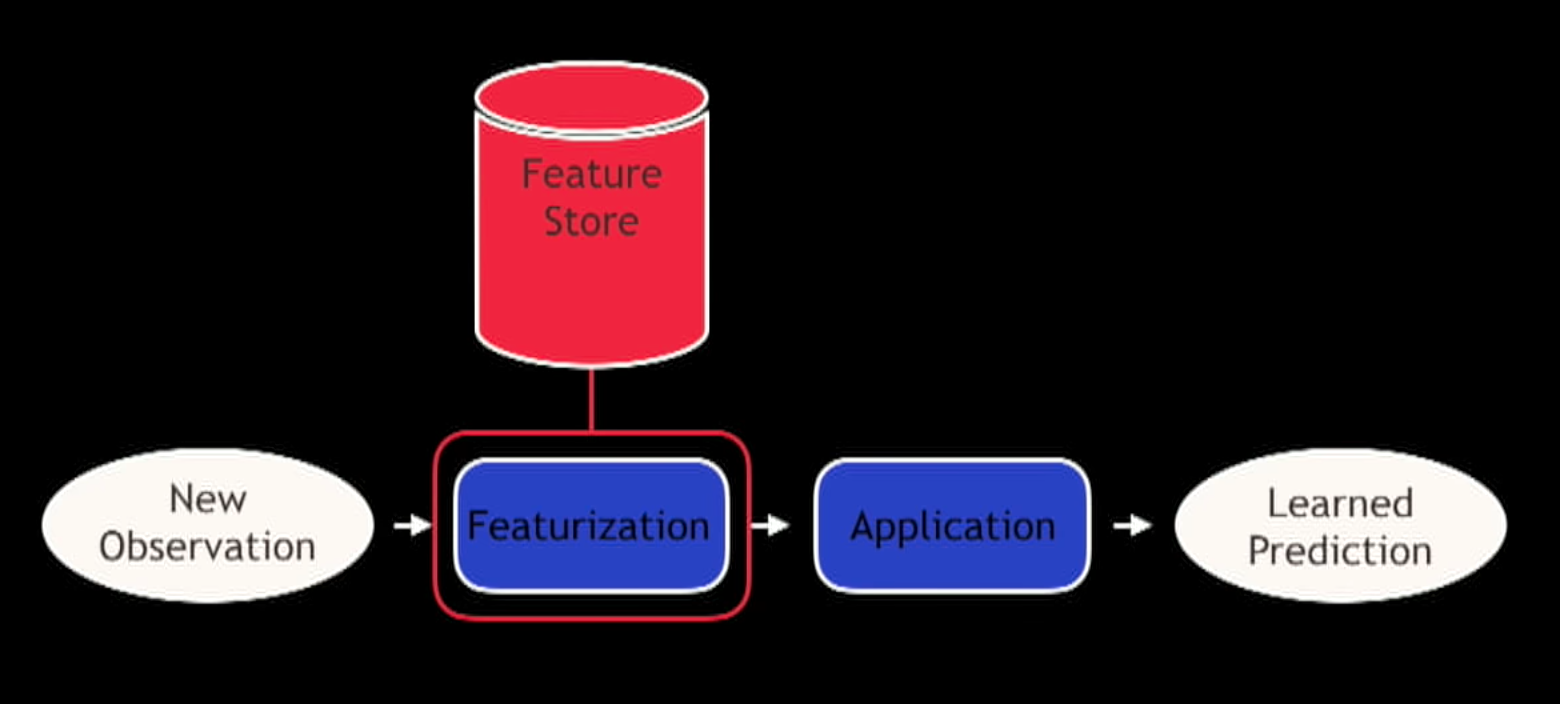
As we saw what we deploy into production is a Featurization step and an Application step.
For Featurization for example if we only get a client id, then we need to go to one or multiple datasources to get the data and do some processing to get it to the point where it looks like a feature vector that we can apply out model to it. This can be very slow.
The Feature Store is kinda a caching layer (pre materializing the feature information for an user or a client) for all that process so you can just look up what features are associated with a model and take the parameters for that model and apply them.
This can have problems if things are out of sync.
You can also cache the output of models.
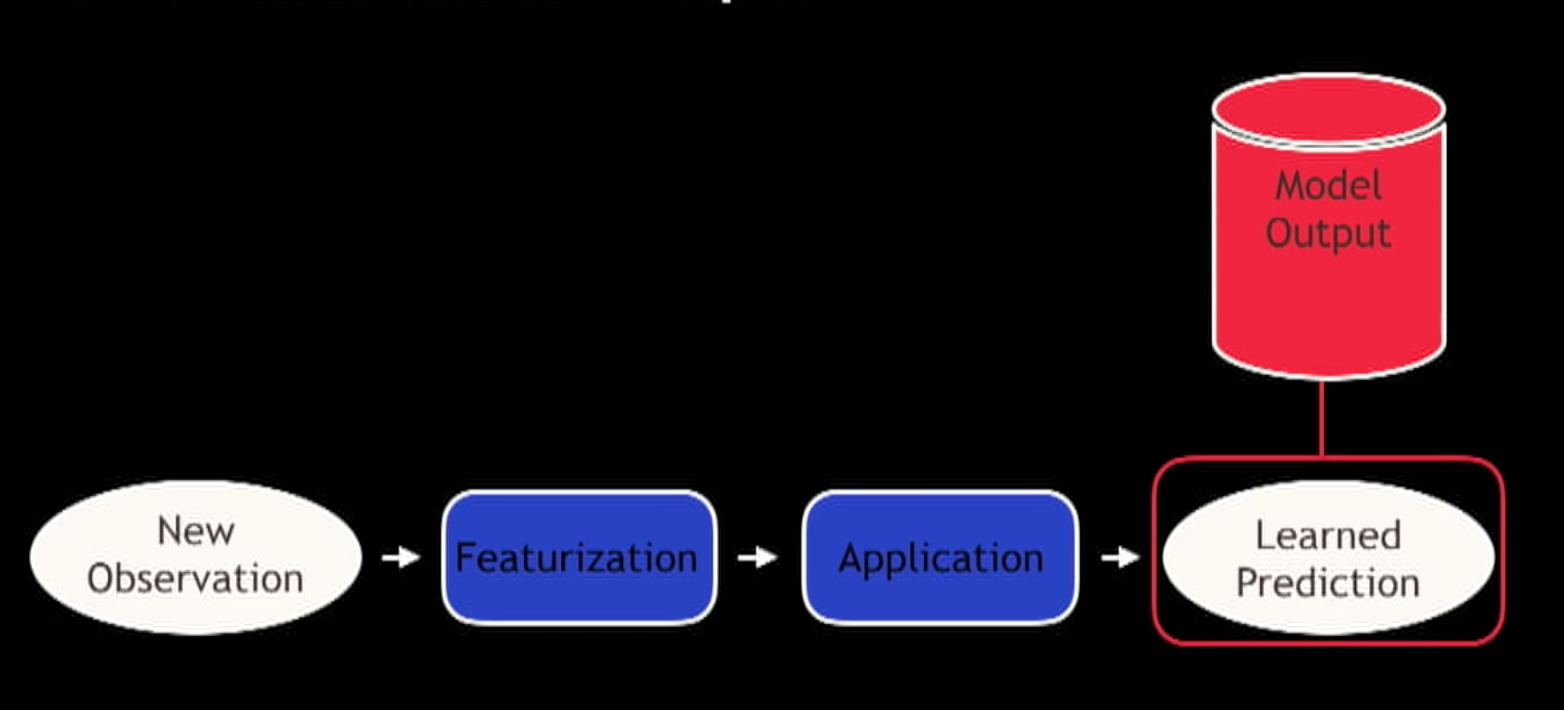
If you don’t have a lot of customers you can have a job that makes a prediction every night, more batch like. This works problems that have bounded domains are not extremely responsive to new inputs.
You can also rewrite models in C :) - DS build a model and handed it to an engineering team to make it fast in another language. This is very error prone.
Organizations which design systems … are constrained to produce designs which are copied of the communication structures of these organizations
- M. Conway. Conway’s lay
The Data Science team structure is very important and it depends on the organization and complexity of the problems you are solving.
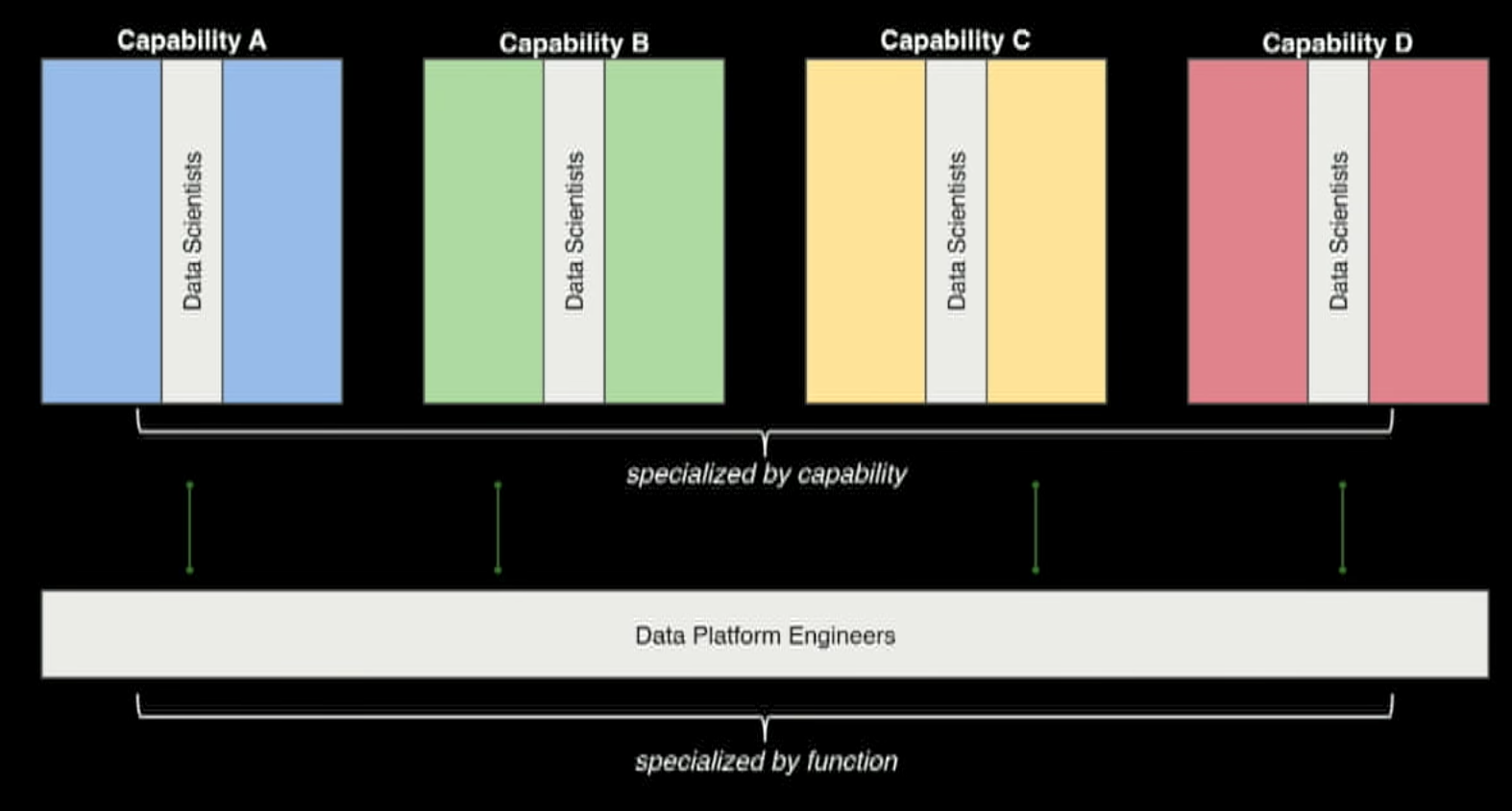
What if DS own a capability? Such as: merchandizing.
Serializing a model
Text based (PMML) or language specific (Pickle).
There is servers PMML for example Open Scoring. The common complain is the limitations in types of models that can be described by PMML and what OpenScoring provides so its not as flexible as Scikit-learn pipelines.
Another way to do this is to think about the serialized model as data and decouple it (almost entirely) from the metadata around (type of the model) and just write the parameters out somewhere, and assume you have written in the service that applies the model the logic that maps correctly the parameters to the actual model you are trying to apply.
There are some problems: you could get out of sync between the model and the service but it works and people seam to use it :)
Does the model…
- Do the thing you want it to do?
- Functionally
- Usefulness
- Both continually through time
- Does it meet your requirements?
- Throughput
- Latency
- Freshness
- Is your team organized in a way that supports your system and its requirements?