Notes for: TGIK 001: A quick tour
This spends a lot of time going trough a k8s install in AWS using Heptio’s tool. Its kinda not as useful anymore since all clouds have a k8s as a service option.
There is no such thing call a k8s master. There are a set of components that make the control plane, its a micro service architecture itself, its fundamentally distributed. Sometimes the control plane can be in a single node so you call it a master but its not a real setup.
You want to put the k8s db (etcd) into its own set of nodes, everything else just centers around that DB and the API server (a policy server that also sit on top of the DB).
etcd is a quorum based DB that is highly consistent, but that comes with some cost of coordination between nodes. Good thing is that it doesn’t lose data! If a nodes goes down all the other ones are ready to pick it up. It has some limits up to 5000-10000 nodes (to git some slow downs), but it actually goes more to how much activity there is on those nodes (pods, cores).
The KUBECONFIG file is basically its own DB since it has relations between the clusters and the users = context. The kubectl cli uses the file in the KUBECONFIG env var so its easy to change it.
There is some things of the control plane that run inside k8s, the kube-system namespace.
Run a sample pod:
kubectl run --generator=run-pod/v1 --image=gcr.io/kuar-demo/kuard-amd64:1 kuard
kubectl get podsPod. For most users pod=container. but also sometimes there is a set of containers that work well as an unit and we want them to run on the same machine and have a level of trusted communication between them.
Its the fundamental thing that k8s cares about placing on machines.
A concrete example is networking sidecar containers for things like Istio, that provide functionality to your application without changing any code. Another example is one container doing data loading and another container doing processing of that data, its important they are in the same node.
kubectl is a fancy curl, it generates a document and pushes it to the server.
You can use --dry-run -o yaml to see what the document is created.
kubectl port-forward kuard 8080:8080 is basically doing an ssh port-forward from an specific pod to the host, use this for development and debugging.
Things are great because you know what to run and k8s finds a place to run it. Things pods don’t do well:
- you have to manage them one by one, you usually want a set of things running specially in production
- once a pod lands on a node, its on that node forever. If the node dies, the pod dies with it
- Imagine a node is “down” but what does “down” really means? it could be a network blip (maybe it just a lot of load) and it will come back in 5 minutes. If k8s decides to relaunch the pod immediately when the node comes back there is going to be 2 copies running in the system at the same time. This could be bad for multiple reasons, logging aggregation is one since there is going to be 2 pods with the same name sending different information
k8s deals with sets very well instead of individual things
Deployments solve this issue. Deployments are a thing built on top of Pods to help with sets of pods.
kubectl run --image=gcr.io/kuar-demo/kuard-amd64:1 kuard --replicas=5
kubectl get podsThis will create 5 pods, with an unique name for each pod. The name is deployment-hash_of_template-uuid.
We cannot use port-forward to access a deployment because it only works with a particular Pod, a Deployment is a set of Pods, how can we access that set of Pods?
A Service helps with that by creating a load-balancer and everytime a request comes in send it to one of the pods.
kubectl expose deployment kuard --type=LoadBalancer --port=80 --target-port=8080A service does this:
- Finds a way to name a set of pods. via labels.
- A Service and a deployment don’t know about each other but a service can target the same set of pods based on the labels the deployment creates for the pods
- Collect all the IP address and put an internal k8s LoadBalancer infront of those, this is the internal system called ClusterIP. Makes it easy to access services from one k8s pod to another through the service abstraction. This only works inside the cluster.
- It takes a port across the cluster and make it so if you hit that port in any node it gets routed to that service. This is a NodePort. This only works inside a VPC, nodes have access to the cluster nodes.
- We can see the NodePort with
kubectl get svc
- We can see the NodePort with
- If its running in a public cloud it can create an External load balancer (e.g. AWS ELB) and point it to all the nodes at the NodePort. This works from the outside world.
You can scale up and down the number of pods of a deployment.
kubectl scale deployment kuard --replicas=10
kubectl edit deploy kuardIf you kubectl edit the deployment you can see everything it was uploaded and also the current status of the deployment, for example number of replicas available.
You can update the version of the deployment by just changing the image that is being deployed.
kubectl set image deployment kuard kuard=gcr.io/kuar-demo/kuard-amd64:2This will perform a rolling upgrade and no connections have been lost.
k8s is declarative, you tell it want you want it to do and it will figure out how to do it.
Probes are way for k8s to talk to your application to get information about it and see if its running and healthy.
Stateful sets are a way to do deployments but back those containers with some data. They are different because the requirements to scale up and down are different. They are basically deployments with extra considerations for attaching volumes.
Daemon sets: I want to run all these containers but maybe i want one per node and in all my machines. Regular users don’t use this that much since you don’t want to think about nodes but its very useful for admins.
The default way of dealing with data you care about in k8s is to attach external storage solution to you pods such as S3, NFS or others. Local Persistent Volumes are a way to allocate some space in one of the nodes so that if a pod (that is using that volume) gets restarted it can reclaim that space. Useful for DBs since if you need to reboot everything it can find the data it had before. Using this you don’t have to pin the pod to a particular node but k8s will do this automatically since it know that volume is running in that node.
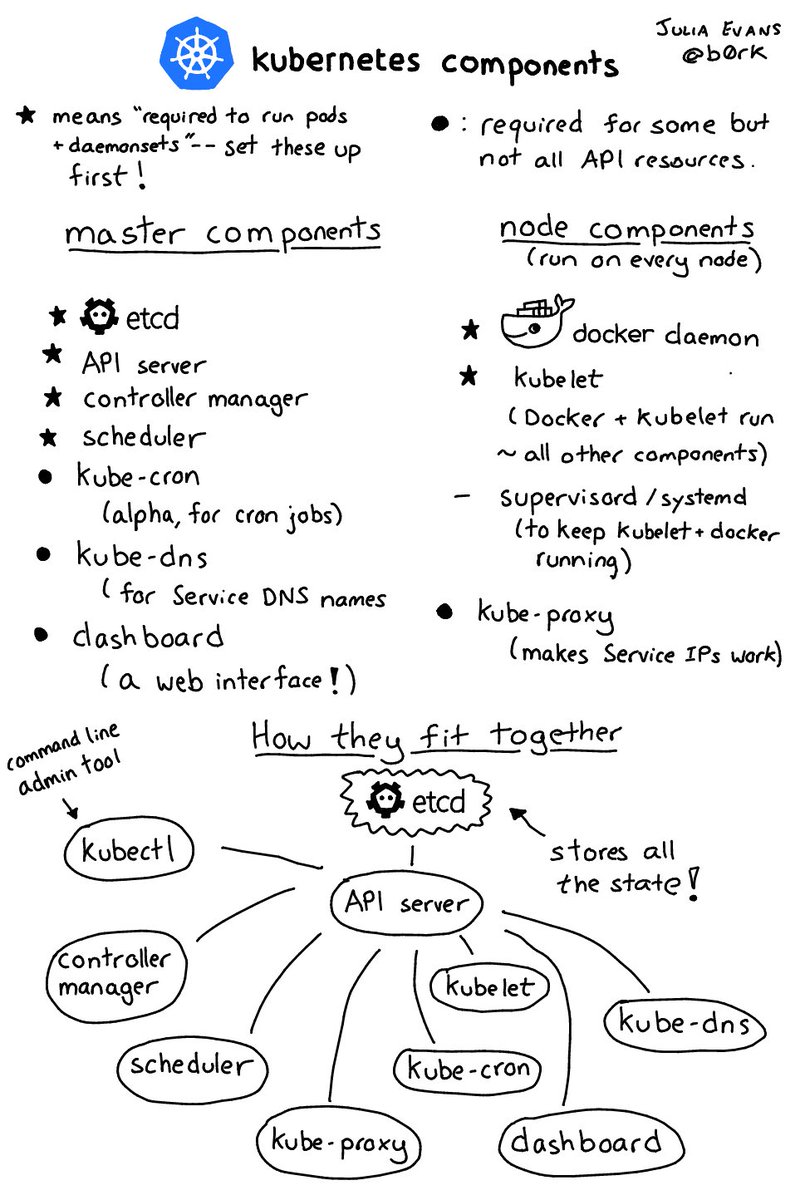
Nice diagram by Julia Evans.