Notes for: Fast.ai 2018 - Lesson 2: Image Classification with CNN
Overfitting is when the model generalizes only to the training data but not to more data. For image classification it would be learning only features of the training images but more images.
The best way to avoid overfitting would be to add more data. This can be also achieved in a way by doing data augmentation. This is using the train data and change it in a way, for images is for example zooming in, moving them around, flipping them and stuff like that.
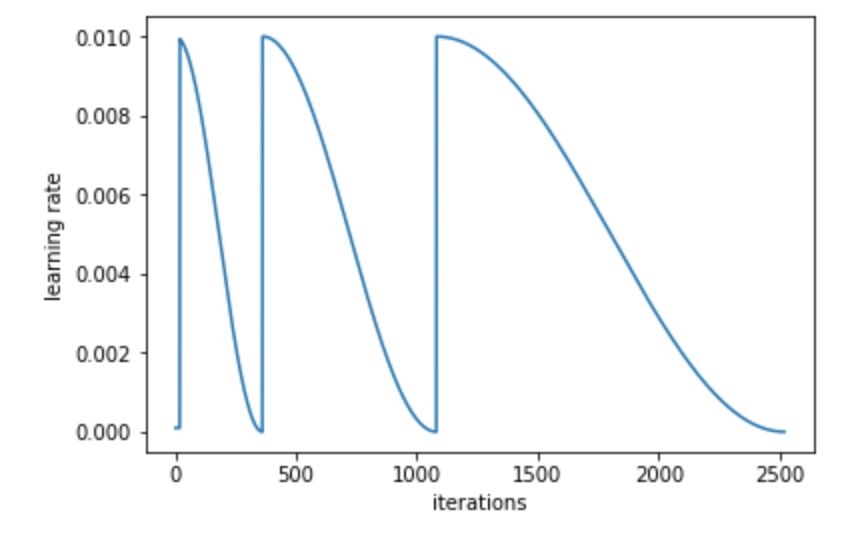
Stochastic Gradient Decent with restarts: As we get closer to the minimum we want to decrease the learning rate to get exactly to the right spot. This is called Learning rate annealing, more on this:
- A naive way is to do it a little bit manual, use one LR until it stops working, reduce it by 10 and repeat
- A better approach is to pick a function like a line but a cosine tends to work better, cosine annealing
- We can extend the cosine annealing with an increase bump of LR to get out of minimums that don’t generalize better
- We change the LR based on cosine annealing every mini batch
- Another possible improvement could be to save the weights in at multiple points while decreasing the LR, taking snapshots and do something with them, for example an ensemble
- Another thing to do is to increase the speed of decrease for a cycle, you usually want to fail fast but go slower as you get closer to the minimum
Fine tuning: Take a model with some weights and freeze some layers (usually the first ones) and train only on the final layers that produce an output.
When doing fine tuning we can use different learning rates for different parts of the model, for example a big learning rate for the final layers and a smaller LR for the early layer (closer to the data).
Test Time Augmentation (TTA): Sometimes the test images have not the same size of the model or simply get confused by an extra object on the image and the prediction is incorrect. We can solve this by using augmentation on the test data. So we (usually randomly select and) apply some augmentations on each image of the test/valid set and we make a prediction in those and the original image. Then take the average of all the prediction as the real result.
Steps to train a world-class image classifier:
- Data augmentation, use precompute model
- Find a good initial learning rate: based on the highest rate when the loss is clearly improving
- Freeze layers and train last layer for 1-2 epochs
- Train last layer with data augmentation for 2-3 epochs with one cycle on the cosine annealing
- Unfreeze all layers
- Set early layers to 3x-10x lower learning rate than the higher later, maybe even more divisions of Learning Rates for different layers
- This depends a lot on the actual problem, if the problem is similar to image net not need to train a lot the initial layers, if its different like medical images those layers might require more work
- Find a good initial LR again: based on the highest rate when the loss is clearly improving
- Train full network with cosine annealing plus making the cycles have longer lengths until overfitting the model
Tip: when you don’t have a lot of data or your model is overfitting: We can train using small images (e.g. 224x224) and then just change the images for bigger images (e.g. 299x299). This looks like a good way to avoid overfitting and maybe even get better results.
When you get a Cuda Out of Memory error you need to restart the kernel, there is no way to come back.
In general make batches as big as possible until you run out of memory
If loss in the validation set is (a lot) lower than the loss in the training set then we are under-fitting, we should train longer.