From zero to storm cluster for scikit-learn classification
Apache storm is a new technology that allows to do real-time computation that its been in the big data news lately and I was curious to try it to see if its really good or is a just the new map-reduce.
One of the first (and no brainer) ideas I had was to do real-time classification of a scikit-learn model, the main issue was that storm is Java and I didn’t want to all the integration between Java and Python but after I saw in the pydata videos that the people at Parsely already took some of that pain out with their new streamparse library I had no more excuses to try it.
Storm cluster
I decided to deploy a storm cluster and after failing to use their EC2 scripts I decided to do it myself using salt. I found an amazing step by step tutorial from Michael Noll that explains how to deploy everything, including the a the zookeeper quorum (a first time from me too).
Is important to note that Michael Noll has some nice scripts to deploy everything using puppet and vagrant, but since I don’t like puppet I decided to recreate some of his work on salt which it was very straight forward since there are already some zookeeper states for salt so I only had to leverage that to create some storm states.
The states I created are very extensible and can extended to many instances using salt-cloud as described in the documentation.
scikit-learn
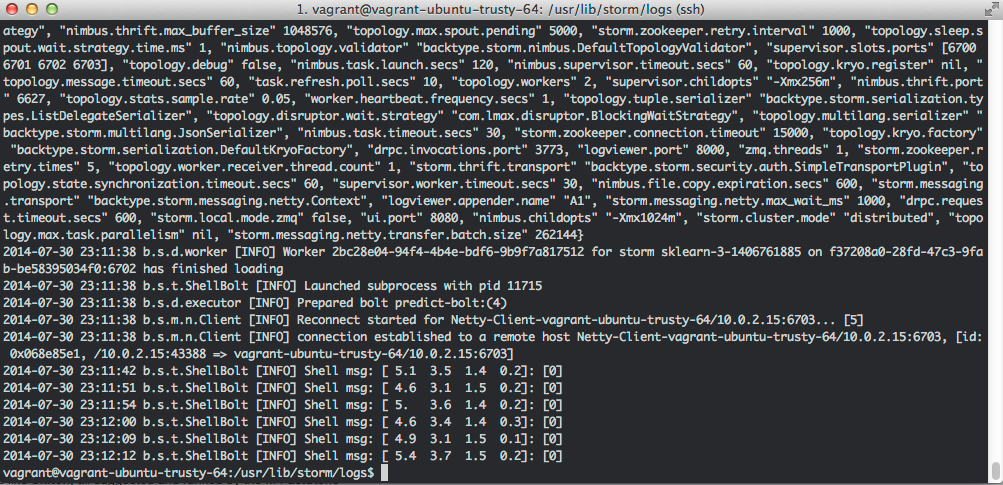
After having the storm cluster up and running I needed to solve a different issue: most storm topologies examples do a very simple calculation, e.g. word count, they don’t need to load anything (big) to do their calculation.
The scikit-learn classification is a little bit more complex since it needs to load the model before doing the calculation and you don’t want to load the model in every storm process in the same machine. Thats where memory mapping and joblib comes handy, you can load the model once into memory once and other processes can use the same model into memory to do the calculation.
To deploy the pickled model into the storm cluster I used salt again to just download the model from github. The example I did uses a tiny SVM on the iris dataset but the idea can be easily extended to download bigger models from S3 for example.
streamparse
streamparse is a nice library from the people at Parsely that makes easy to create storm topologies using python and a little bit of clojure. The library is young but it looks promising, my main complain is that it tries to take care of more that it should: python environments.
They try to solve the virutalenvs problem using fabric and the classic virtualenv, a valid approach for a small storm cluster and basic python libraries. I believe that this problem should be solve by a tool like salt in case you have a big cluster and also using conda for the python environmenst since it gives you an easier use of the to use the scientific libraries.
So I used salt to solve the virutalenv problems using one of my conda states and then I had to recreate some of the streamparse submit so it does not create any virutalenvs, just submit the topology to the storm-nimbus.
Conclusion
I am very happy with the results since I was able to do this by leveraging a lot of useful tools making it very easy to develop and deploy, making it very scalable and reproducible.
I still need to test more storm to take my final decision and see were it is really useful. Is the complexity of maintaining a zookeeper quorum and storm cluster really worth it? Or do I just keep using 0MQ?
One bonus idea is to make the storm spouts and bolts more useful by integrating with the outside world, for now it just keeps predicting the same data forever, maybe a good idea would be to do some websockets as spout and bolts to make a nice real-time UI.
All the code and documentation on how to make everything is on github: storm-sklearn